 which is a link to details of the change and where it applies. A PDFs of the printed version is available.
which is a link to details of the change and where it applies. A PDFs of the printed version is available.
https://iupac.qmul.ac.uk/misc/glycp.html
World Wide Web version Prepared by G. P. Moss
School of Physical and Chemical Sciences, Queen Mary University of London,
Mile End Road, London,
E1 4NS, UK
g.p.moss@qmul.ac.uk
These Rules are as close as possible to the published version drafted by Nathan Sharon (The Weizmann Institute of Science, Rehovot, Israel) [see Eur. J. Biochem., 1986, 159, 1-6; 1989, 185, 485;Glycoconjugate J., 1986, 3, 123-134; J. Biol. Chem., 1987, 262, 13-18; Pure Appl. Chem., 1988, 60, 1389-1394; Amino Acids and Peptides, 1990, 21, 329-334; and in Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pp 84-89. Copyright IUPAC and IUBMB; reproduced with the permission of IUPAC and IUBMB]. If you need to cite these rules please quote these references as their source. In setting up the World Wide Web version an error was detected and appropriate corrections have been made. The changes have been marked by which is a link to details of the change and where it applies. A PDFs of the printed version is available.
Any comments should be sent to the current secretary of the Committee, or any other member of the Committee
Important Note: This version is formatted using the font symbol for Greek letters. If you cannot see a Delta (a triangle) in quotation marks next "Δ" click here for a version where Greek letters are created using graphic images.
Various types of compound consisting of carbohydrates covalently linked with other types of chemical constituent are classified under the general name of glycoconjugates. The major groups of glycoconjugates are the glycoproteins, glycopeptides, peptidoglycans, glycolipids and lipopolysaccharides. The first three of tbese are considered in the present document. The nomenclature of glycolipids has been the subject of an earlier document [1], which is now under revision.
As early as 1907, when very little was known about glycoproteins, they were defined by the Committees on Protein Nomenclature of the American Society of Biological Chemists and the American Physiological Society as 'compounds of the protein molecule with a substance or substances containing a carbohydrate group other than a nucleic acid' [2]. In spite of the enormous progress in our knowledge of the occurrence, biosynthesis, properties and functions of the glycoproteins, this definition remains appropriate.
Glycoproteins are widely distributed in all forms of life, with the possible exception of the eubacteria. They occur in cells, both in soluble and membrane-bound forms, as well as in the extracellular matrix and in extracellular fluids. The commonest glycoproteins are those in which the carbohydrate is linked to the protein by glycosyl linkages. Glycosylation represents one of the important co-translational and post-translational modifications of proteins.
The term 'glycoprotein' should include proteoglycans, which in the past were considered as a separate class of compound. Proteoglycans are those glycoproteins whose carbohydrate moieties consist of long, unbranched chains of alternating residues of hexosamine and uronic acid or galactose, often sulfated. Such polysaccharides belong to the class of glycosaminoglycans. Proteoglycans were not considered as glycoproteins in the past because their carbohydrate seemed to differ so greatly from the comparatively small, branched, usually unsulfated carbohydrate units, devoid of repeating units, found in other glycoproteins. Another reason was their unique distribution: the proteoglycans are found mainly in connective tissues, where they contribute to the organization and physical properties of the extracellular matrix. It is known, however, that proteoglycans too are glycosylated proteins, synthesized by the action of glycosyltransferases, and that repeating disaccharide units are present in typical glycoproteins as well. Proteoglycans are therefore considered to be a subclass of glycoproteins.
The terms 'protein glucosylation (or glycosylation)' and 'glucosylated (or glycosylated) hemoglobin' have been used improperly to refer to the products of non-enzymic reactions between glucose or other sugars and free amino groups of proteins. Compounds formed in this manner are not glycosides, however, as they result from the formation of a Schiff base followed by Amadori rearrangement to 1-deoxyketos-1-yl derivatives of the proteins. For example, the product of the reaction between glucose and hemoglobin is not glucosylated hemoglobin but N-(1-deoxyfructos-1-yl)hemoglobin. The term 'glycation' is suggested for all such reactions that link a sugar to a protein or peptide. The product of glycation is a glycoprotein, or, in the special case of the reaction with hemoglobin, glycohemoglobin. When appropriate, a more precise name such as (1-deoxyfructos-1-yl)hemoglobin may be used.
Peptidoglycans, sometimes referred to as mureins, are glycoconjugates found only in bacterial cell walls. Although they are also composed of carbohydrates and amino acids covalently linked, they are a distinct class of compound as (a) they do not contain a protein portion; (b) they contain sugars not found elsewhere; and (c) they consist of linear polysaccharides (of the class of glycosaminoglycan) crosslinked by oligopeptides, thus forming a huge and rigid network.
No official nomenclature of glycoproteins, glycopeptides and peptidoglycans has been available hitherto. In drawing up the present document, we follow the general rules of biochemical nomenclature [3], especially the more recent ones on carbohydrates [4-7] and amino acids and peptides [8].
2.1. Glycoproteins, proteoglycans and glycosaminoglycans
A glycoprotein is a compound containing carbohydrate (or glycan) covalently linked to protein. The carbohydrate may be in the form of a monosaccharide, disaccharide(s). oligosaccharide(s), polysaccharide(s), or their derivatives (e.g. sulfo- or phospho-substituted). One, a few, or many carbohydrate units may be present. Proteoglycans are a subclass of glycoproteins in which the carbohydrate units are polysaccharides that contain amino sugars. Such polysaccharides are also known as glycosaminoglycans.
2.2. Glycopeptides,glyco-amino-acids and glycosyl-amino-acids
A glycopeptide is a compound consisting of carbohydrate linked to an oligopeptide composed of L- and/or D-amino acids. A glyco-amino-acid is a saccharide attached to a single amino acid by any kind of covalent bond. A glycosyl-amino- acid is a compound consisting of saccharide linked through a glycosyl linkage (O-, N- or S-) to an amino acid. (The hyphens are needed to avoid implying that the carbohydrate is necessarily linked to the amino group.)
A peptidoglycan consists of a glycosaminoglycan formed by alternating residues of D-glucosamine and either muramic acid {2-amino-3-O-[(R)-1-carboxyethyl]-2-deoxy-D-glucose} or L-talosaminuronic acid (2-amino-2-deoxy-L-taluronic acid), which are usually N-acetylated or N-glycoloylated. The carboxyl group of the muramic acid is commonly substituted by a peptide containing residues of both L- and D-amino acids, whereas that of L-talosaminuronic acid is substituted by a peptide consisting of L-amino acids only.
3.1. Form of carbohydrate in glycoproteins
In many glycoproteins (e.g. plasma glycoproteins such as human α1-acid glycoprotein or fetuin) the carbohydrate is in the form of oligosaccharides, linear or branched, the latter containing up to about 20 monosaccharide residues; glycoproteins containing mono- or disaccharide units are also known [e.g. collagens, fish antifreeze glycoproteins, sheep submaxillary (or submandibular) glycoproteins], as well as those that contain oligosaccharides that cansist of repeating units of N-acetyllactosamine (e.g. band 3 of the human erythrocyte membrane).
A proteoglycan is a protein glycosylated by one or more (up to about 100) glycosaminoglycans (Table 1). The glycosaminoglycans of the proteoglycans are linear polymers of up to about 200 repeating disaccharide units that consist of a hexosamine (D-glucosamine or D-galactosamine) alternating with a uronic acid (D-glucuronic or L-iduronic) or a neutral sugar (D-galactose). The hexosamines are usually N-acetylated, and in some of the glycosaminoglycans the D- glucosamine is N-sulfated. Varying degrees of sulfation occur in other positions of the hexosamines as well as on the L-iduronic acid. The chain of repeating units is linked to the protein by an oligosaccharide of a structure different from the repeating units. This linkage region (Table 1) is identical in most of the proteoglycans (chondroitin sulfates, dermatan sulfate, heparin, and heparan sulfate), but is different in keratan sulfate. This last glycosaminoglycan contains repeating units of N-acetyllactosamine that are O-sulfated. Because of their content of uronic acid and/or ester sulfate, the glycosaminoglycans of the proteoglycans are anionic polyelec- trolytes and have been referred to as 'acidic glycosaminoglycans' (equivalent to the older term 'acid mucopolysaccharides'). Proteoglycans may also contain one or more oligosaccharides of structures similar to those found in other glycoproteins.
Table l . Structure of glycosaminoglycans
Based mainly on Lindahl, U. & Höök, M. (1978), Annu. Rev. Biochem. 47, 385-417; and Roden, L. (1980) in The biochemistry of glycoproteins and proteoglycans (Lennarz, W. J. ed.). pp. 267-371, Plenum Press. New York.
| Name | Repeating disaccharide | Sulfation | Linkage region |
|---|---|---|---|
| Hyaluronic acid | GlcNAc(β1![[arrow right]](../greek/ARROWR.GIF) 4)GlcA(β13) 4)GlcA(β13) | None | not proved to be linked to protein |
| Chondroitin 4- and 6-sulfate | GalNAc(β14)GlcA(β13) | GalNAc-4-O-sulfate, 6-O-sulfate or hybrids | GlcA(β13)Gal(βl3)Gal(βl4)Xyl(β1O)Ser |
| Dermatan sulfate | GalNAc(β14)GlcA(β13) and 4)L-IdoA(α13) | GalNAc-4-O-sulfate, or 6-O-sulfate; L-iduronic acid may be sulfated at position 2 | GlcA(β13)Gal(β13)Gal(β14)Xyl(β1O)Ser |
| Heparin and heparan sulfate | GlcNR(α14)GlcA(β14) and GlcNR(α1 4)L-IdoA(α14) | In heparin (highly sulfated), R mostly SO3H, little acetyl; in heparan sulfate generally less SO3H and more acetyl than in heparin. Some of the N-acetyl- D-glucosamine is 6-O-sulfated, and some of the L-iduronic acid is 2-O-sulfated | GlcA(β13)Gal(β13)Gal(β14)Xyl(β1O)Ser |
| Keratan sulfate | GlcNAc(β13)Gal(β14) | GlcNAc-6-O-sulfate; Gal-6-O-sulfate | see Fig. 1 |
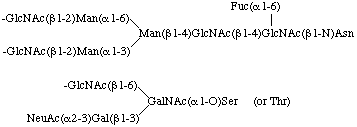
Fig. 1. Linkage region of corneal and skeletal keratan sulfate. The upper structure shows the linkage region in keratan sulfate type I (corneal); the lower shows that in keratan sulfate type II (skeletal)
Several diseases of proteoglycan metabolism are recognized, including the Hunter and Hurler syndromes; they are referred to as mucopolysaccharidoses, but strictly speaking should go by the term 'glycoproteinoses', which encompasses other diseases of glycoprotein metabolism such as mannosidosis and fucosidosis.
A particular glycoprotein may occur in forms that differ in the structure of one or more of its carbohydrate units, a phenomenon known microheterogeneity. Such differences may affect both the size and charge of individual glycoproteins; occasionally, the differences may be solely due to changes in linkage position in a carbohydrate unit. For example, chicken ovalbumin contains a single glycosylated amino-acid residue (Asn-293), but more than a dozen different oligosaccharides have been identified at that site. In proteoglycans, individual glycosaminoglycan chains may differ in structure, e.g. the degree of sulfation, the ratio of glucuronic acid to L-iduronic acid, and chain length. Proteoglycans are therefore highly polydisperse, in contrast to typical glycoproteins which, in spite of their microheterogeneity, are not markedly polydisperse in their molecular size.
Glycopeptides, glyco-amino-acids, glycosyl-amino-acids and glycosylpeptides are obtained by enzymic or chemical cleavage of glycoproteins, or by chemical or enzymic synthesis.
Examples of glycosyl-amino-acids that constitute the common linking compounds between the carbohydrate and protein in glycoproteins are as follows (Table 2): 2-acetamido-N-(L-aspart-4-yl)-2-deoxy-β-D-glucopyranosylamine, i.e. N4-(N-acetyl-β-D-glucosaminyl)asparagine, which is abbreviated to (GlcNAc-)Asn (parentheses here around the carbohydrates placed next to the symbol for an amino-acid residue indicate substitution on its side chain: see section 3AA-17.2 in ref. 8); O3-(N-acetyl-α-D-galactosaminyl)serine and threonine, (GalNAc-)Ser and (GalNAc-)Thr; O-β-D-xylosylserine, (Xyl-)Ser; O5-α-D-galactosylhydroxylysine [This compound could more stricthy be described as 5(α-D-galactopyranosyloxy)-L-lysine, but hydroxylysine is regarded as a trivial name [8] so names are based on it.], (Gal-)Hyl; and β-L-arabinosylhydroxyproline [Hydroxyproline is the trivial name for trans-4-hydroxy-L-proline.], (L-Ara-)Hyp. Another example of a glyco-amino-acid is [Man9-GlcNAc(β14)-GlcNAc-]Asn, isolated from a proteolytic digest of soybean agglutinin. Such a compound may be referred to as oligosaccharylasparagine.
Table 2. Commonly occurring glycosyl-amino-acids
Based on Sharon, N. & Lis, H. (1982) in The proteins, 3rd edn (Neurath, H. & Hill, R. L., eds) vol. 5, pp. 1-144, Academic Press, New York
| Example | Structure | Occurence |
|---|---|---|
| N-Glycosidea β-N-Acetylglucosaminylasparagine, (GlcNAc-)Asn | 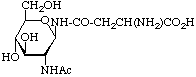 | widely distributed in animals, plants and microorganisms |
| O-Glycosides α-N-Acetylgalactosaminylserine or -threonine, (GalNAe-)Ser, (GalNAc-)Thr | 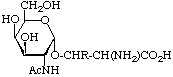 | glycoproteins of animal sources |
| β-Xylosylserine (Xyl-)Ser | 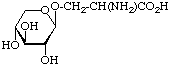 | proteoglycans, human thyroglobulin |
| β-Galactosylhydroxylysine (Gal-)Hyl | 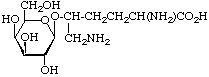 | collagens |
| β-L-Arabinosylhydroxyproline, (L-Ara-)Hyp | 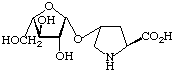 | plant and algal glycoproteins |
a Traditionally the term 'glycoside' referred explicitly to O-linked compounds; we use the term 'N-glycoside' rather than 'nitrogen analogue of glycoside', which is unnecessarily cumbersome.
If desirable, the linkage between carbohydrate and protein may be indicated by the locants N- or O-. The locant N- is used for the N-glycosyl linkage to asparagine. N-Linked oligosaccharides are divided into two major classes: the N-acetyllactosamine type containing N-acetyl-D-glucosamine, D-mannose, D-galactose, L-fucose and sialic acid, and the oligomannose type containing N-acetyl-D-glucosamine and a variable number of D-mannose residues. Structures containing both oligomannose- and N-acetyllactosamine-type oligosaccharides are designated as hybrid type. Examples of N-glycoproteins (or N-glycosylproteins) are chicken ovalbumin, pig ribonuclease, human α1-acid glycoprotein and soybean agglutinin.
The locant O- is used for O-glycosyl linkage to serine. threonine, hydroxylysine or hydroxyproline. Sheep submaxillary glycoprotein, collagen, fish antifreeze glycoproteins and potato lectin are O-glycoproteins (or O-glycosylproteins).
Two types of carbohydrate-peptide linkage in the same protein or peptide chain may be indicated by a combination of the locants. Thus, calf fetuin, procollagen, human erythrocyte membrane glycophorin and human chorionic gonadotropin are N-,O-glycoproteins (or N-,O-glycosylproteins).
3.6. Asialoglycoproteins and asialo-agalactoglycoproteins
Glycoproteins from which the sialic acid has been removed (by treatment with enzyme or mild acid) are designated by the prefix asialo-, e.g. asialo-α1-acid glycoprotein, and asialofetuin. Removal of both sialic acid and galactose results in asialo-agalactoglycoproteins.
3.7. Condensed representation of sugar chains
For writing the structure of sugar chains, the non-reducing terminus of the carbohydrate chain should always be on the left-hand end (see ref. 6). Current practice allows the use of either an extended form (a) or a condensed form (b) which allows structures to be shown in one line as well as in two or more, and in which the longest chain should always be the the main chain:
a) Extended form
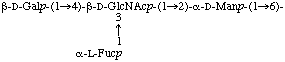
b) Condensed form in two lines
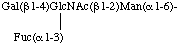
or condensed form in one line
Gal(β14)[Fuc(α13)]GlcNAc(β12)Man(α16)-
The condensed form is still unnecessarily long, however, and there should be no serious loss if it is shortened further by (i) omitting locants of anomeric carbon atoms, (ii) omitting parentheses around the specification of linkage, and (iii) omitting hyphens if desired. We therefore suggest a more condensed or short form of writing (c):
c) Short form
Galβ4(Fucα3)GlcNAcβ2Manα6-
Similarly a glycopeptide sequence, represented in the condensed form in two lines as
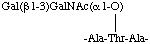
or in the condensed form in one line as
-Ala-[Gal(β13)GalNAc(α1O)]Thr-Ala-
may be written in the short form in two lines as
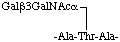
or in the short form in one line as
-Ala-(Galβ3GalNAcα)Thr-Ala-
3.8. Representation of N-linked oligosaccharides
As a rule, N-linked oligosaccharides contain a common pentasaccharide core as follows:
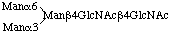
For the sake of uniformity, the location of substitution should be written as above in accordance with Haworth's representation of the pyranose structure of monosaccharides, in analogy with the glycogen molecule.
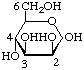
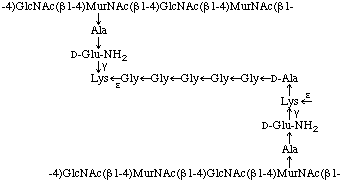
Fig. 2. Primary structure of a peptidoglycan which the cross-linkage between adjacent peptide-substituted polysaccharides is mediated by an interpeptide bridge consisting of Lys-[Gly]5
In peptidoglycans, peptide units of adjacent polysaccharides (glycosaminoglycans) may be cross-linked by a peptide bond between the C-terminal alanine residue of one peptide subunit and the w-amino group of the diamino-acid residue of the other (e.g. L-lysine or meso-diaminopimelic acid), thereby giving rise to a giant macromolecule that forms the rigid cell wall ('sacculus'). This macromolecule is known to occur as a monomolecular layer between the inner and outer membrane in Gram-negative bacteria and as a multimolecular layer, often associated covalently or non-covalently with various additional compounds (teichoic acids, neutral polysaccharides. etc.) in Gram-positive bacteria.
Extensive investigations of peptidoglycans in thousands of bacterial strains demonstrated the existence of more than 100 chemotypes in the eubacteria [9]. The peptidoglycans of eubacteria have been classified into two major groups (A and B) and several subgroups according to the mode of cross-linkage. Within group A two main subgroups are recognized: one in which the C-terminal alanine residue is directly bound to the w-amino group of the diamino acid at position 3 of the peptide subunit of an adjacent polysaccharide (glycosaminoglycan) and one in which the cross-linkage is mediated by an interpeptide bridge consisting of either one or up to 5 amino-acid residues (e.g. Lys-[Gly]5-type, Fig. 2). Depending on the kind of diamino acid at position 3 and the amino acids serving as interpeptide bridges, many variations of these subgroups of murein are known. In the peptidoglycan types of group B, the cross-linkage does not occur at position 3 of the peptide subunit but at position 2, utilizing the α-carboxyl group of the D-glutamic residue. The interpeptide bridge must contain a diamino acid, which may be lysine. ornithine or diaminobutyric acid, in either L- or D-configuration. As a second special characteristic of the group B peptidoglycan types, the L-alanine residue at position 1 of the peptide subunit is replaced by either glycine or serine.
In the archaebacteria, several organisms contain a peptidoglycan that differs in certain respects from those described above, typical for the eubacterta [10, 11]. It consists of a polysaccharide formed by alternating (β13)-linked N-acetylated residues of D-glucosamine or D-galactosamine and (β13)-linked N-acetylated residues of L-talosaminuronic acid, and a peptide containing exclusively L-amino acids attached to the carboxyl group of L-talosaminuronic acid. The peptide units of adjacent polysacchartdes may be cross-linked by a peptide bond between the g-carboxyl group of the glutamic acid of one peptide subunit and the α-amino group of the lysine residue of the other, thus giving rise to the rigid cell wall of the methanogenic bacteria. This multimolecular layer is often associated covalently, but also non-covalently, with neutral polysaccharides. Only a few chemotypes of such peptidoglycans have so far been described.
1. IUPAC-IUB Commission on Biochemical Nomenclature (CBN). The nomenclature of lipids. Recommendations 1974. Biochem. J. 171, 21-35 (1978); Eur. J. Biochem. 79, 11-21 (1977); Hoppe-Seyler's Z. Physiol. Chem. 358, 617-631 (1977); Lipids 12, 455-468 (1977); ref. 3. pp. 122-132 (1978).
2. Joint Recommendations of the Physiological and Biochemical Committees on Protein Nomenclature, R. H. Chittenden, O. Folin, W. J. Gies, W. Koch, T. B. Osborne, P. A. Levene, J. A. Mandel, A. P. Mathews & L. B. Mendel (1908) J. Biol. Chem. 4, XLVIII-LI.
3.International Union of Biochemistry (1978) Biochemical nomenclature and related documents, The Biochemical Society, London.
4. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN), Conformational nomenclature for five and six-membered ring forms of monosaccharides and their derivatives. Recommendations 1980, Arch. Biochem. Biophys. 207, 469-472 (1981); Eur. J. Biochem. 111, 295-298 (1980); Pure Appl. Chem. 53, 1901-1905 (1981) [see also 1996 recommendations].
5. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN), Nomenclature of unsaturated monosaccharides, Recommendations 1980, Eur. J. Biochem. 119, 1-3 (1981) and 125, 1 (1982); Pure Appl. Chem. 54, 207-210 (1982) [see also 1996 recommendations].
6. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN). Abbreviated terminology of oligosacchande chains. Recommendations 1980. Arch. Biochem. Biophys. 220, 325-329 (1983); Eur. J. Biochem. 126, 433-437 (1982); J. Biol. Chem. 257, 3347-3351 (1982); Pure Appl. Chem. 54, 1517-1522 (1982) [see also 1996 recommendations].
7. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN), Symbols for specifying the conformation of polysaccharide chains. Recommendations 1981, Eur. J. Biochem. 131, 5-7 (1983); Pure Appl. Chem. 55, 1269-1272 (1983).
8. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN), Nomenclature and symbolism for amino acids and peptides, Recommendations 1983, Biochem. J. 219, 345-373 (1984); Eur. J. Biochem. 138, 9-37 (1984); Pure Appl. Chem. 56, 595-624 (1984).
9. Schleifer, K. H. & Kandler, O. (1972) Bacteriol. Rev. 36, 407-477.
10. Kandler, O. (1982) Zbl. Bakt. Hyg. I. Abt. Orig. C3, 149-160.
11. König, H., Kralik, R. & Kandler, O. (1982) Zbl. Bakt. Hyg. I. Abt. Orig. C3, 179-191.
5. APPENDIX: IMPLIED CONFIGURATIONS AND RING SIZES
In the condensed system of symbols for sugar residues the common configuration and ring size (usually pyranose) are implied in the symbol. Thus, Gal denotes D-galactopyranose; Man, D-mannopyranose; Fuc, L-fucopyranose; GlcNAc, 2-acetamido-2-deoxy-D-glucopyranose or N-acetyl-D-glucosamine; Neu5Ac (which may be abbreviated to NeuAc) N-acetylneuraminic acid. The symbol Sia stands for sialic acid, a general term that can also be used when the exact structure is unknown. Whenever the configuration or ring size is found to differ from the common one it must be indicated by using the appropriate symbols for the extended system. The configuration of amino acids is L unless otherwise noted. Although symbols such as Gal and Man are useful in representing oligosaccharide structures they should not be used in the text to represent monosaccharides.