https://iupac.qmul.ac.uk/misc/pnuc1.html
World Wide Web version Prepared by G. P. Moss
School of Physical and Chemical Sciences, Queen Mary University of London,
Mile End Road, London,
E1 4NS, UK
g.p.moss@qmul.ac.uk
These Rules are as close as possible to the published version [see Eur. J. Biochem., 1983, 131, 9-15; Proceedings of the 16th Jerusalen Symposium "Nucleic Acids, the Vectors of Life" (edited B Pullman and J Jortner) 1983, 559-565; Pure Appl. Chem., 1983, 55, 1273-1280; and in Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pp 115-121. Copyright IUPAC and IUBMB; reproduced with the permission of IUPAC and IUBMB]. If you need to cite these rules please quote these references as their source. A PDF of the printed version is available.
Any comments should be sent to the current secretary of the Committee, or any other member of the Committee
Important Note: This version is formatted using the font symbol for Greek letters. If you cannot see a Delta (a triangle) in quotation marks next "Δ" click here for a version where Greek letters are created using graphic images.
Several conventions and notations for polynucleotide conformation have been used by various authors [1-9]. To overcome this confusion, the Joint Commission on Biochemical Nomenclature appointed a panel of experts to review the problem and make recommendations. Their proposals, together with suggestions from the members of JCBN and other scientists, are presented here as recommendations that have been approved by IUPAC and IUB. The nomenclature proposed here is consistent with that recommended for polypeptide conformation [10] as well as with recommendations for polysaccharide conformation [12] and stereochemistry of synthetic polymers [13]. The recommendations on polypeptide conformation [10] also cover general problems of specifying the conformation of biopolymers. Nomenclature of nucleic acids and symbols for their constituents follow published recommendations [14].
RECOMMENDATIONS
1. GENERAL PRINCIPLES OF NOTATION
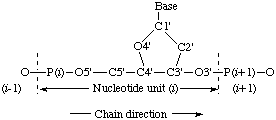
The atoms of the main chain are denoted in Fig. 1. The direction of progress of a polynucleotide chain is from the 5'-end to the 3'-end of the sugar residue.
Fig. 1. Designation of chain direction and main chain atoms ofNotesi th unit in a polynucleotide chain
a) The definition of chain direction is in accord with the definition of the nucleotide unit (see 1.2).
b) The definition of chain direction with respect to the sugar carbon atoms of the nucleotide unit is consistent with the alternative description of polynucleotide sequences as progressing from the 3'-end of one unit to the 5'-end of the next through the phosphate group, i.e. in the chain sequence L-(3'![[arrow right]](../greek/ARROWR.GIF) 5 ')-M-(3'5 ')-N, etc. (written as LpMpN or L-M-N for a known sequence, or L, M, N for an unknown sequence).
5 ')-M-(3'5 ')-N, etc. (written as LpMpN or L-M-N for a known sequence, or L, M, N for an unknown sequence).
1.2. Definition of a Nucleotide Unit
A nucleotide unit is the repeating unit of a polynucleotide chain; it comprises three distinct parts: the D-ribose or 2-deoxy-D-ribose (2-deoxy-D-erythro-pentose) sugar ring, the phosphate group, and the purine or pyrimidine base. The sugar ring and the phosphate group form the backbone of the polynucleotide chain; the base ring linked to the sugar residue consitutes the side chain as shown in Fig. 1.
A nucleotide unit is defined by the sequence of atoms from the phosphorus atom at the 5'-end to the oxygen atom at the 3'-end of the pentose sugar; it includes all atoms of the sugar and base rings.
Specific units (i, j ... or 3, 4, 5, etc.) are designated by the letter or number in brackets. The units are numbered sequentially in the chain direction, starting at the first nucleotide residue, irrespective of the presence or absence of a phosphate group at the 5'-terminal unit.
The same numbering, A(1), pU(2), pU(3) etc. would apply to the sequence ApUpUp- and pApUpUp-.
The atom numbering of the constituents of the nucleotide unit is shown in Fig.1, 2 and 3. The numbering scheme for the bases shown in Fig.2 is the same as that recommended by IUPAC (Rule B-2.11 on page 58 in [15] and on page 5567 in [16]). The atoms belonging to the sugar moiety are distinguished from those of the base by the superscript prime mark on the atom number. Atoms are specified by the appropriate number after the symbol, e.g. C2, N3 (for base) and C1', C5', O5' (for sugar).
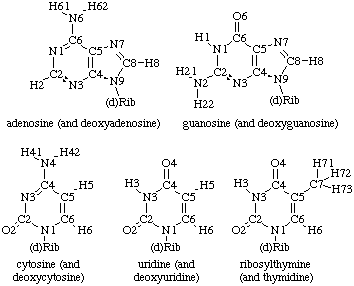
Fig.2. The atom numbering for the bases of common nucleosides and nucleotides. Hydrogen atoms carry the same numbers as the heavy atoms to which they are attached. The name in parenthesis applies when the 'd' in parenthesis in the formula is presentAtoms of a specific unit (i, j . . . or 3, 4, 5) may be designated by the letter or number of the unit in brackets e.g. O3'(i ), P(i+ 1) and N1(3), C2'(4).
Hydrogen atoms carry the same number as the heavy atoms to which they are attached, e.g. base ring H6 (pyrimidine) and H8 (purine) as shown in Fig.2; sugar ring H1', H2' etc, as shown in Fig. 3. Where there is more than one hydrogen atom (such as at C5' of the sugar ring), the atoms are designated numerically (e.g. H5'1 and H5'2); H5'1 and H5'2 correspond to the pro-S and pro-R positions [17], respectively (Fig. 3). [See also addenda for numbering of phosphate oxygen atoms.]
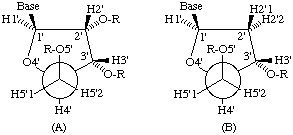
Fig. 3. Designation of sugar ring atoms and hydrogen atoms. (A) In β-D-nucleosides and nucleotides; (B) in their 2'-deoxy derivativesThe atom-numbering scheme for the 2'-deoxyribonucleotide chain is the same as that for the ribonucleotide chain shown in Fig. l. The numbering for the sugar ring atoms of both D-ribose and 2-deoxy-D-ribose rings is shown in Fig.3. (Note the absence of a prime in '2-deoxy-D-ribose' in the previous sentence; C2' of a nucleotide is C2 of its ribose residue.) The two hydrogen atoms attached to the C2' atom of a nucleoside are denoted by H2'1 and H2'2, corresponding to the pro-S and pro-R positions respectively (Fig. 3).
The hydrogen atoms of hydroxyl groups are specified as in O5'H, O3'H and O2'H, where appropriate, whereas the hydroxyl groups are specified as OH5', etc.
Notes
a) Designation of the sugar-ring oxygen atom by O4' conforms with chemical nomenclature; it has been widely but inaccurately denoted by O1' in the past.
b) Detailed atom numbering for the modified nucleotides is not considered here.
c) The numerical designation of C5' and C2' methylene hydrogen atoms supersedes that introduced by Davies [9].
1.4. Bonds, Bond Lengths and Interatomic Distances
Covalent bonds are denoted by a hyphen between atoms, e.g. O5'-C5', C5'-H5'1 and C2-N3. Atoms in specified nucleotide units are indicated by putting the number of the unit in parentheses, e.g. O5'(i )-C5'(i ). O3'(i )-P(i+ 1). Bond lengths are denoted by b(O5', C5') or b[O3'(i ), P(i+ 1)]. Use of the symbol l for bond length is avoided because it can be confused with the numeral 1 and because l is used for vibration amplitude in electron diffraction (section 1.4 of [10]). Hydrogen bonds are denoted by a dotted line, with the donor atom being written first, if it can be specified, e.g. intramolecular O5' . . . N3 hydrogen bonding in some purine derivatives or O5'(i ) . . . N3(j ) for intermolecular hydrogen bonding. The position of the hydrogen may also be indicated as in O5'-H . . . N3. Hydrogen-bonded base pairs are considered separately (see section 4.1). Distances between non-bonded atoms are denoted by a dot, e.g. O5'(i ) . O3'(j ).
The bond angle included between three atoms A-B-C is written τ(A, B. C). which may be abbreviated to τ(B) if there is no ambiguity.
If a system of four atoms A-B-C-D is projected onto a plane normal to B-C, the angle between the projection of A-B and the projection of C-D is described as the torsion angle about bond B-C; this angle may also be described as the angle between the plane containing atoms A. B and C, and the plane containing atoms B, C and D. The torsion angle is written in full as θ(A, B, C, D), which may be abbreviated, if there is no ambiguity, to θ(B, C). In the statement of this rule, the angle θ is used as a general angle rather than as referring to any particular bond (see Rule 2 for designation of main-chain torsion angles).
The zero-degree torsion angle (θ = 0°) is given by the conformation in which the projections of A-B and C-D coincide (this is also known as the eclipsed or cis conformation). When the sequence of atoms A-B-C-D is viewed along the central bond B-C, a torsion angle is considered positive when the bond to the front must be rotated clockwise in order that it may eclipse the bond to the rear as shown in Fig. 5A. When the bond to the front must be rotated counterclockwise in order to eclipse the bond at the rear, the angle is considered negative as shown in Fig. 5B.
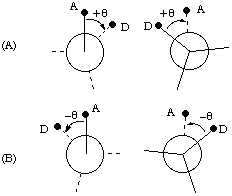
Fig. 5. Newman projections illustrating (A) positive and (B) negative torsion angles. (A) A clockwise turn of the bond containing the front atom about the central bond is needed for it to eclipse the bond to the back regardless of the end from which the system is viewed, hence the value of θ is positive (+θ). (B) A counterclockwise turn of the bond containing the front atom is needed for it to eclipse the bond to the back atom regardless of the end from which the system is viewed; hence the value of θ is negative (-θ)Angles are usually measured from 0° to 360°, but they may be expressed as -180° to +180° when special relationships between conformers need to be emphasized. Illustrations of the definition of torsion angles are shown for positive and negative values of θ in Fig.5A and B respectively. It should be noted that a clockwise turn of the bond containing the front atom about the central bond gives a positive value of θ from whichever end the system A-B-C-D is viewed in Fig. 5A; similar considerations apply to the conformation with a negative torsion angle (Fig. 5B).
If the precise torsion angle for a conformation is not known, it may be convenient to specify it roughly by naming a conformational region. i.e. a range in which the torsion angle lies. For this the Klyne-Prelog nomenclature [17,18], accepted in organic chemistry, is recommended. The relationship between the terms used. ![[plus minus]](../greek/PLUSMIN.GIF) synperiplanar (sp). synclinal (sc). anticlinal (ac) and antiperiplanar (ap), and the magnitudes of the torsion angles are shown in Fig. 6.
synperiplanar (sp). synclinal (sc). anticlinal (ac) and antiperiplanar (ap), and the magnitudes of the torsion angles are shown in Fig. 6.
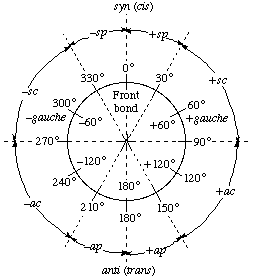
Fig.6. Relationship belween the syn-anti terminology for describing conformational regions [17,18] and the magnitude of the torsion angle 0-360° (or 0The range 0
90° is denoted as syn and the range 180 90° is denoted as anti.Note
In order that conformations described by the torsion angle defined in rule 1.6 be consistent in sign and magnitude with the conformational regions ( syn, anti) shown in Fig. 6. it is necessary, when looking down the BC (or CB) bond, that the front bond A-B (or D-C) should define the zero (0°) position, and that the back bond should define the conformational region.
Examples
a) In Fig. 3 the O5'-C5' bond makes an angle of +60° to C4'-C3' and 300° (-60°) to the C4'-O4' bond. With the O5'-C5' bond defining the zero position these conformations correspond to the +sc and -sc regions, respectively.
b) For the sequence of atoms A-B-C-D as shown in Fig. 5A the same conformation with the torsion angle θ being positive (+θ) is found when looking along either the B-C bond (A to the front) or the C-B bond (D to the front); this conformation is described as +sc. Similarly the conformation designated by a negative value of θ (-θ), shown in Fig.5B, corresponds to the -sc region.
c) See section 2.3. notes (a) and (c). for the example in Fig. 11.
1. Donohue, J. & Trueblood, K. N. (1960) J. Mol. Biol. 2, 363-371.
2. Sasisekharan, V., Lakshminarayanan, A. V. & Ramachandran, G. N. (1967) in Conformation of Biopolymers II (Ramachandran, G. N., ed.) pp. 641-654, Academic Press, New York.
3. Arnott, S. & Hukins, D. W. L. (1969) Nature (Lond.), 224, 886-888.
4. Sundaralingam, M. (1969) Biopolymers, 7, 821-860.
5. Lakshminarayanan, A. V. & Sasisekharan, V. (1970) Biochim. Biophys. Acta, 204, 49-59.
6. Olson, W. K. & Flory, P. J. (1972) Biopolymers, 11, 1-23.
7. Sundaralingam, M., Pullman, B., Saenger, W., Sasisekharan, V. & Wilson, H. R. (1973) in Conformations of Biological Molecules and Polymers (Bergman, E. D. & Pullman, B., eds) pp. 815-820, Academic Press, New York.
8. Seeman, N. C., Rosenburg, J. M., Suddath, F. L., Kim, J. J. P. & Rich, A. (1976) J. Mol. Biol. 104, 142-143.
9. Davies, D. B. (1978) in NMR in Molecular Biology (Pullman, B., ed.) pp. 509-516, Reidel, Dordrecht.
10. IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Abbreviations and symbols for the description of the conformation of polypeptide chains, Tentative rules 1969 (approved 1974), Arch. Biochem. Biophys. 145, 405-421 (1971); Biochem. J. 121, 577-585 (1971); Biochemistry, 9, 3471-3479 (1970); Biochim. Biophys. Acta, 229, l-17 (1971); Eur. J. Biochem. 17, 193-201 (1970); J. Biol. Chem. 245, 6489-6497 (1970); Mol. Biol. (in Russian) 7,289-303 (1973); Pure Appl.Chem. 40, 291-308 (1974); also on pp. 94-102 in [11]. [Also in Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 73-81.]
11. International Union of Biochemistry (1978) Biochemical Nomenclature and Related Documents, The Biochemical Society, London. [2nd edition, Portland Press, 1992]
12. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN) Symbols for specifying the conformation of polysaccharide chains, Recommendations 1981, Eur. J. Biochem. 131, 5-7 (1983). [Also in Pure Appl. Chem., 1983, 55, 1269-1272 and Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 177-179.
13. IUPAC Commission on Macromolecular Nomenclature (CMN), Stereochemical definitions and notations relating to polymers, Pure Appl. Chem. 53, 733-752 (1981).
14. IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Abbreviations and symbols for nucleic acids, polynucleotides and their constituents, Recommendations 1970, Arch. Biochem. Biophys. 145, 425-436 (1971); Biochem. J. 120, 449-454 (1970); Biochemistry, 9, 4022-4027 (1970); Biochim. Biophys. Acta, 247, 1-12 (1971); Eur. J. Biochem. 15, 203-208 (1970) corrected 25, l (1972); Hoppe-Seyler's Z. Physiol. Chem. (in German) 351, 1055-1063 (1970); J. Biol. Chem. 245, 5171-5176 (1970); Mol. Biol. (in Russian) 6, 167-174 (1972); Pure Appl. Chem. 40, 277-290 (1974); also on pp. 116-121 in [11].
15. International Union of Pure and Applied Chemistry (1979) Nomenclature of Organic Chemistry, Sections A, B, C, D, E, F and H, (Rigandy, J. & Klesney, S. P., eds) Pergamon Press, Oxford.
16. IUPAC Commission on the Nomenclature of Organic Chemistry (CNOC) Definitive rules for nomenclature of organic chemistry, J. Am. Chem. Soc. 82, 5545-5574 (1960).
17. IUPAC Commission on Nomenclature of Organic Chemistry (CNOC) Rules for the nomenclature of organic chemistry, Section E: Stereochemistry, Recommendations 1974, Pure Appl. Chem. 45, 11-30 (1976); also on pp. 473-490 in [15] and on pp. 1-18 in [11].
18. Klyne, W. & Prelog, V. (1960) Experientia, 16, 521-523.
Return to Conformation of Biopolymers Home Page
Return to Biochemical Nomenclature Committees Home Page
Return to IUPAC Chemical Nomenclature Home Page
Return to main IUBMB Biochemical Nomenclature Home Page