Abbreviations and Symbols for the Description of Conformations of Polynucleotide Chains
Recommendations 1982
Continued from General Principles of Notation
CONTENTS
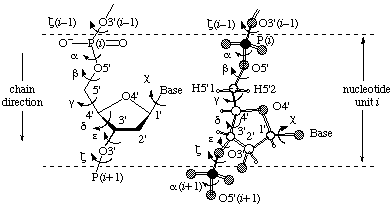
The notations used to designate the various torsion angles in the nucleotide unit are indicated in three sections: sugar-phosphate backbone chain, sugar ring and sugar-base side chain.
2.1. Sugar-Phosphate Backbone Chain (main chain)
The backbone of a polynucleotide chain consists of a repeating unit of six single bonds as shown in Fig. 1, viz. P-O5', O5'-C5', C5'-C4', C4'-C3', C3'-O3' and O3'-P. The torsion angles about these bonds are denoted, respectively, by the symbols α, β, γ, δ, ε, ζ. The symbols α(i )-ζ(i ) are used to denote torsion angles of bonds within the
Fig. 4. Section of a polynucleotide backbone showing the atom numbering and the notation for torsion angles. (A) Conventional representation; (B) absolute stereochemistry. [See addenda for numbering of the phosphate oxygen atoms.]
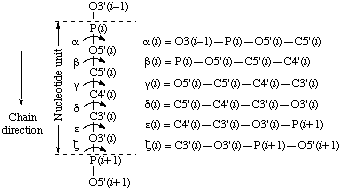
Fig. 7. Torsion angles for backbone conformations of theNotei th nucleotide in polynucleotide chains
The recommended α-ζ notation differs from the φ, ψ, ω notation [4, 7] adopted by many workers and from an earlier α-ζ notation [8].
A substantial majority of the subcommittee favoured the α-ζ notation because it is convenient to remember for a backbone repeat of six bonds. The recommended α-ζ notation is the second of the systems proposed by Seeman et al. [8] and was chosen because it starts at the phosphorus atom which is the first atom of the nucleotide unit, has the highest atomic number, and is the only atom of its kind in the backbone.
2.2.1. Endocyclic Torsion Angles
The sugar ring occupies a pivotal position in the nucleotide unit because it is part of both the backbone and the side chain. In order to provide a complete description of the ring conformation, it is necessary to specify the endocyclic torsion angles for the ring as well as the bond lengths and bond angles. The five endocyclic torsion angles for the bonds O4'-C1', C1'-C2', C2'-C3', C3'-C4' and C4'-O4' are denoted by the symbols, ν0, νl, ν2, ν3 and ν4, respectively.
The sequence of atoms used to define each backbone torsion angle is shown in Fig. 8; e.g. ν0 refers to the torsion angle of the sequence of atoms C4'-O4'-Cl'-C2', etc.
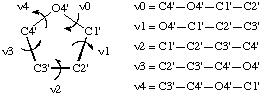
Fig. 8. Torsion angles in sugar rings of β-D-nucleosides and nucleotidesNotes
a) The backbone torsion angle δ and the endocyclic torsion angle ν3 both refer to rotation about the same bond, C4'-C3'. Both angles are needed for complete description of the main-chain and sugar-ring conformations in some studies.
b) The notation τ0-τ4 previously used [4, 19-21] to represent torsion angles about the bonds in the sugar ring is superseded by the present notation (ν). which is consistent with polysaccharide nomenclature [12]. The symbol τ is now used to denote a bond angle, which is consistent with polypeptide nomenclature [10].
Since the sugar ring is generally non-planar, its conformation may need designation. If four of its atoms lie in a plane, this plane is chosen as a reference plane, and the conformation is described as envelope (E); if they do not, the reference plane is that of the three atoms that are closest to the five-atom, least-squares plane, and the conformation is described as twist (T) [22, 23]. Atoms that lie on the side of the reference plane from which the numbering of the ring appears clockwise are written as superscripts and precede the letter (E or T); those on the other side are written as subscripts and follow the letter (Fig. 9). These definitions [23] mean that atoms on the same side of the plane as C5 in D-ribofuranose derivatives are written as preceding superscripts.
Notes
a) The present E and T notations for puckered forms of the sugar ring conform to those recommended for the conformational nomenclature of five and six-membered rings of monosaccharides and their derivatives [23].
b) The E/T notation has superseded the endo/exo description [24], in which atoms now designated by superscripts were called endo, and those now designated by subscripts were called exo. Fig.10 shows both systems of designation. Examples:
c) Symmetrical twist conformations, in which both atoms exhibit equal displacements with respect to the five-atom plane' are denoted by placing the superscript and subscript on the same side of the letter T, e.g. 23T, 43T, etc.
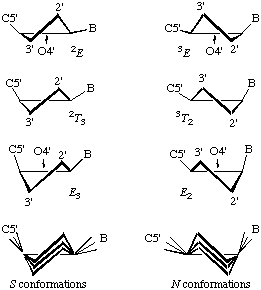
Fig.9. Diagrammatic representation of sugar-ring conformations of β-D-nucleosides and their relation to the pseudorotational N-type and S-type conformers (Section 2.2.3.). The purine or pyrimidine base is represented by B. (Figure adapted from that of Saenger [25])
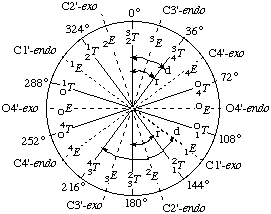
Fig. 10. The pseudorotational pathway of the D-aldofuranose ring, showing the relation between phase angle of pseudorotation P (0-360°), the envelope (E) and twist (T) notations and the endo and exo notations. N-Type conformations correspond to the northern half (P = 02.2.3. Pseudorotational Analysis90°) and S-type correspond to the southern half of the pseudorotational cycle. The symbols 'r' and 'd' represent the usual range of P values for N and S conformations of ribo- (r) and 2'-deoxyribo- (d) furanose rings of β-D-nucleosides and nucleotides. (Diagram adapted from the work of Altona and Sundaralingam [26])
The sugar ring conformation has also been described by Altona and Sundaralingam [26] using the concept of pseudorotation, which has been found advantageous in describing the conformational dynamics of the sugar ring [27].
Each conformation of the furanose ring can be unequivocally described by two pseudorotational parameters: the phase angle of pseudorotation, P, and the degree of pucker, ψm. A standard conformation (P=0°) is defined with a maximally positive C1'-C2'-C3'-C4' torsion angle [i.e. the symmetrical 23T form], and P has value 0-360°. Conformations in the upper or northern half of the circle (P = 0±90°) are denoted N and those in the southern half of the circle (P = 18090°) are denoted S conformation. The relationship between P and the endo/exo and T/E notations is illustrated in Fig. 10. It may be seen that the symmetrical twist (T) conformations arise at even multiples of 18° of P and the symmetrical envelope (E) conformations arise at odd multiples of 18° of P.
Note.
The present designation of the degree of pucker (ψm) differs from the original notation (τm) of Altona and Sundaralingam [26] in order to avoid confusion with the notation for bond angles.
The torsion angle about the N-glycosidic bond (N-C1') that links the base to the sugar is denoted by the symbol χ which is the same as the notation used to denote side-chain torsion angles in polypeptides [10]. χ(i ) denotes the torsion angle in the
The sequence of atoms chosen to define this angle is O4'-C1'-N9-C4 for purine and O4'-C1'-N1-C2 for pyrimidine derivatives. Thus when χ = 0° the O4'-C1' bond is eclipsed with the N9-C4 bond for purine and the N1-C2 bond for pyrimidine derivatives. The definitions of torsion angles (section 1.6) of the N-glycosidic bond are illustrated, looking along the bond, in Fig. 11.
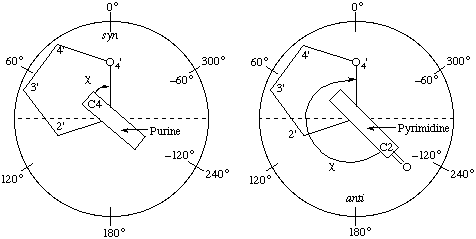
Fig. 11. Diagrammatic represeniation of the N-glycosidic bond torsion angle χ and the syn and anti regions for purine and pyrimidine derivatives. The purine derivative (left) is viewed down the N9-C1' bond and is shown in the +sc conformation. The pyrimidine derivative (right) is viewed down the N1-C1' bond and is shown in the -ac conformation. The sugar ring is shown as a regular pentagonNotes
a) The choice of bond sequence to define χ is based on accepted chemical nomenclature [13] and, at the same time, the use of the terms syn and anti to describe different conformational regions of χ for purine and pyrimidine derivatives is now consistent with accepted chemical nomenclature (Rule 1.7). viz.
Examples of syn and anti conformations are shown in Fig. 11. In the new convention most conformations formerly described as syn and anti remain syn and anti respectively, except the high-anti region which may be described as -synclinal (-sc). Rule 1.7.
b) Many of the conventions for defining the torsion angle of a bond in nucleic acids [1-7, 28, 29] have been based on the sugar ring O4' atom [4, 5, 25] or C2' atom [3, 29] in conjunction with the base ring C8(Pur)/C6(Pyr) atoms [4, 5, 29] or base ring C4(Pur)/C2(Pyr) atoms [3, 28]. Approximate relationships between the definitions of torsion angles have been summarised by Sundaralingam [30], and these aid the comparison of conformations described in the older literature. A substantial portion of the literature has used the nomenclature based on sugar ring O4'-C1' and base ring N9-C8(purine) and N1-C6(pyrimidine). χold is related to the present definition χnew by the relation,
c) Following the definitions of conformational regions in Rule 1.7 and Fig. 6 the anti conformation of the pyrimidine example in Fig. 11 corresponds to the -anticlinal (-ac) conformation and the syn conformation of the purine derivative corresponds to the +synclinal (+sc) conformation.
2.4. Orientation of Side Groups
For the precise definition of the orientation of any pendant groups specification of the torsion angle about the exocyclic bond is necessary. The exocyclic torsion angle may be denoted by the symbol η with a locant to indicate the atom to which it refers. Examples:
Ribose Rings. The symbol η2' may be used to denote the torsion angle about the C2'-O2' bond for the sequence of atoms Cl'-C2'-O2'-X where X = H, CH3, PO32-, etc. If no confusion is possible, the symbol η (without any additional index) may be used for the C2'-O2' bond.
Base. Torsion angles for bonds in base rings e.g. C6-N6 in adenine, C2-N2 in guanine and C4-N4 in cytosine may be specified by η6, η2 and η4, respectively.
When the groups are substituted by hydrogen atoms only (see Fig. 2), the relevant dihedral angles defined by the sequence rules are:
The rules may be adapted for substituted base and sugar rings, such as those of minor components of tRNA. Examples:
1-Methyladenosine: use η11, η12, η13 for the C-CH3 group conformation.
2'-O-Methyladenosine: use η2' for rotation about the C2'-O2' bond and η2'1, η2'2, η2'3 for the OCH3 group.
Note.
Recommendations governing the description of conformations of side chains and derivatives follow the sequence rules (Rule 2) and the side-chain rules (Rule 4) of the recommendations for polypeptides [10].
3.1. Polarity of Hydrogen Bonds
In specifying a hydrogen bond the atom covalently linked to the hydrogen atom is mentioned first, as in X-H . . . Y. The polarity of a hydrogen bond is from the hydrogen-atom donor to the acceptor.
3.2. Geometry of Hydrogen Bonds
The hydrogen bond may be described by extension of the nomenclature of sections 3.1, 1.4, 1.5 and 1.6, so that for the hydrogen bond in the system Ci)-X(i )-H(i ) . . . Y(k)-C(k) the following symbols may be used:
Where the positions of hydrogen atoms are not available the following may be used:
A regular helix is strictly of infinite length, with the torsion angles in a nucleotide unit the same for all units. Two or more polynucleotide chains may associate in a helical complex by hydrogen bonding between base pairs. Torsion angles for each residue may differ for different chains in the same double, triple, etc. complex.
A helical segment of a polynucleotide chain may be described in terms of torsion angles of the nucleotide units or in terms of the helix characteristics summarized in section 4.2.
Base pairs with different geometries have been observed. These geometries should be denoted by the appropriate hydrogen-bonding scheme specifying both the heterocyclic base (e.g. Ade, Ura, Gua, Cyt) and the heteroatoms involved in the hydrogen bonding. In some cases it is also desirable to specify the nucleotide unit (i, j, etc.). Typical examples are: for a Watson-Crick A:U base pair:
for a reversed Watson-Crick A:U base pair:
In the description of helices or helical segments the following symbols should be used:
n = number of residues per turn
h = unit height (translation per residue along the helix axis)
t = 360°/n = unit twist (angle of rotation per residue about the helix axis)
n = pitch height of helix = n.h.
A polynucleotide may be accurately described in terms of the polar atomic co-ordinates ri, φi, zi where for each atom i, ri is the radial distance from the helix axis and φi, and zi are the angular and height differences respectively, relative to a reference point. The reference point should be either a symmetry element, as in RNA and DNA, or the C1' atom of a nucleotide if no symmetry element between polynucleotide chains is present.
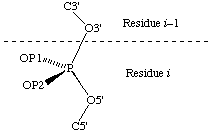
Addenda. Atom numbering in polynucleotides
Since publication of the recommendations on Abbreviations and Symbols for the Description of Conformations of Polynucleotide Chains [31] an extension has been published in the JCBN/NC-IUB Newsletter. This is listed below and cross references to it is incorporated into the main document in this World Wide Web version.
From the JCBN/NC-IUB Newsletter 1984 [32]
The recommendations for describing the conformations of polynucleotide chains [31] gave designations for all polynucleotide atoms except for the two otherwise non-bonded atoms on phosphorus. We recommend that the pro-S atom should be designated OP1 and the pro-R atom OP2, as follows:
1. Donohue, J. & Trueblood, K. N. (1960) J. Mol. Biol. 2, 363-371.
2. Sasisekharan, V., Lakshminarayanan, A. V. & Ramachandran, G. N. (1967) in Conformation of Biopolymers II (Ramachandran, G. N., ed.) pp. 641-654, Academic Press, New York.
3. Arnott, S. & Hukins, D. W. L. (1969) Nature (Lond.), 224, 886-888.
4. Sundaralingam, M. (1969) Biopolymers, 7, 821-860.
5. Lakshminarayanan, A. V. & Sasisekharan, V. (1970) Biochim. Biophys. Acta, 204, 49-59.
6. Olson, W. K. & Flory, P. J. (1972) Biopolymers, 11, 1-23.
7. Sundaralingam, M., Pullman, B., Saenger, W., Sasisekharan, V. & Wilson, H. R. (1973) in Conformations of Biological Molecules and Polymers (Bergman, E. D. & Pullman, B., eds) pp. 815-820, Academic Press, New York.
8. Seeman, N. C., Rosenburg, J. M., Suddath, F. L., Kim, J. J. P. & Rich, A. (1976) J. Mol. Biol. 104, 142-143.
9. Davies, D. B. (1978) in NMR in Molecular Biology (Pullman, B., ed.) pp. 509-516, Reidel, Dordrecht.
10. IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Abbreviations and symbols for the description of the conformation of polypeptide chains, Tentative rules 1969 (approved 1974), Arch. Biochem. Biophys. 145, 405-421 (1971); Biochem. J. 121, 577-585 (1971); Biochemistry, 9, 3471-3479 (1970); Biochim. Biophys. Acta, 229, l-17 (1971); Eur. J. Biochem. 17, 193-201 (1970); J. Biol. Chem. 245, 6489-6497 (1970); Mol. Biol. (in Russian) 7,289-303 (1973); Pure Appl.Chem. 40, 291-308 (1974); also on pp. 94-102 in [11]. [Also in Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 73-81.]
11. International Union of Biochemistry (1978) Biochemical Nomenclature and Related Documents, The Biochemical Society, London. [2nd edition, Portland Press, 1992]
12. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN) Symbols for specifying the conformation of polysaccharide chains, Recommendations 1981, Eur. J. Biochem. 131, 5-7 (1983). [Also in Pure Appl. Chem., 1983, 55, 1269-1272 and Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 177-179.
13. IUPAC Commission on Macromolecular Nomenclature (CMN), Stereochemical definitions and notations relating to polymers, Pure Appl. Chem. 53, 733-752 (1981).
14. IUPAC-IUB Commission on Biochemical Nomenclature (CBN) Abbreviations and symbols for nucleic acids, polynucleotides and their constituents, Recommendations 1970, Arch. Biochem. Biophys. 145, 425-436 (1971); Biochem. J. 120, 449-454 (1970); Biochemistry, 9, 4022-4027 (1970); Biochim. Biophys. Acta, 247, 1-12 (1971); Eur. J. Biochem. 15, 203-208 (1970) corrected 25, l (1972); Hoppe-Seyler's Z. Physiol. Chem. (in German) 351, 1055-1063 (1970); J. Biol. Chem. 245, 5171-5176 (1970); Mol. Biol. (in Russian) 6, 167-174 (1972); Pure Appl. Chem. 40, 277-290 (1974); also on pp. 116-121 in [11].
15. International Union of Pure and Applied Chemistry (1979) Nomenclature of Organic Chemistry, Sections A, B, C, D, E, F and H, (Rigandy, J. & Klesney, S. P., eds) Pergamon Press, Oxford.
16. IUPAC Commission on the Nomenclature of Organic Chemistry (CNOC) Definitive rules for nomenclature of organic chemistry, J. Am. Chem. Soc. 82, 5545-5574 (1960). 17. IUPAC Commission on Nomenclature of Organic Chemistry (CNOC) Rules for the nomenclature of organic chemistry, Section E: Stereochemistry, Recommendations 1974, Pure Appl. Chem. 45, 11-30 (1976); also on pp. 473-490 in [15] and on pp. 1-18 in [11]. [Also in Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 1-18.]
18. Klyne, W. & Prelog, V. (1960) Experientia, 16, 521-523.
19. Arnott, S. & Hukins, D. W. L. (1972) Biochem. Biophys. Res. Commun. 47, 1504-1509.
20. Pullman, B. Perahia, D. & Saran, A. (1972) Biochim. Biophys. Acta, 269, 1-14.
21. Saran, A. & Govil, G. (1971) J. Theor. Biol. 33, 407-418.
22. Hall, L. D. (1963) Chem. Ind. (Lond.) 950-951.
23. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN) Conformational nomenclature for five and six-membered ring forms of monosaccharides and their derivatives, Recommendations 1980, Arch. Biochem. Biophys. 207, 469-472 (1981); Eur. J. Biochem. 111, 295-298 (1980); Pure Appl. Chem. 53, 1901-1905 (1981).
24. Jardetzky, C. D. (1960) J. Am. Chem. Soc. 82, 229-233.
25. Saenger, W. (1973) Angew. Chem. Int. Ed. Engl. 12, 591-601.
26. Altona, C. & Sundaralingam, M. (1972) J. Am. Chem. Soc. 94, 8205 - 8212.
27. Altona, C. & Sundaralingam, M. (1973) J. Am. Chem. Soc. 95, 2333-2334.
28. Kang, S. (1971) J. Mol. Biol. 58, 297-315.
29. Saenger, W. & Scheit, K. H. (1970) J. Mol. Biol. 50, 153-169.
30. Sundaralingam, M. (1973) in Conformations of Biological Molecules and Polymers (Bergman, E. D. & Pullman, B., eds) pp. 417-455, Academic Press, New York.
31. IUPAC-IUB Joint Commission on Biochemical Nomenclature (JCBN), Abbreviations and Symbols for the Description of the Conformations of Polynucleotide Chains, Recommendations 1982, Eur. J. Biochem. 131, 9-15 (1983); Pure Appl. Chem. 55, 1273-1280 (1983) and on pp. 115-121 in Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 115-121. [Also Proceedings of the 16th Jerusalem Symposium "Nucleic Acids, the Vectors of Life" (edited B Pullman and J Jortner) 1983, 559-565.]
32. Newsletter 1984, Arch. Biochem. Biophys., 1984, 229, 237-245; Biochem. Internat., 1984, 8, following p 202; Biochem. J., 1984, 217, I-IV; Biosci. Rep., 1984, 4, 177-180; Chem. Internat., 1984(3), 24-25; Eur. J. Biochem., 1984, 138, 5-7; Hoppe-Seyler's Z. Physiol. Chem., 1984, 365, I-IV; Trends Biochem. Sci., 1984, 9, various issues.