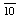 ), or a range (e.g. 8-12), as appropriate. However, two n's should not appear in the same formula unless equal length is implied. When equal length is not the case, different letters should be used, such as m, j, k.
), or a range (e.g. 8-12), as appropriate. However, two n's should not appear in the same formula unless equal length is implied. When equal length is not the case, different letters should be used, such as m, j, k.
IUPAC-IUB Commission on Biochemical Nomenclature (CBN)
(Polymerized Amino Acids) Revised Recommendations (1971)
https://iupac.qmul.ac.uk/misc/polypep.html
World Wide Web version prepared by G. P. Moss
School of Physical and Chemical Sciences, Queen Mary University of London,
Mile End Road, London, E1 4NS, UK
e-mail g.p.moss@qmul.ac.uk
These recommendations are as close as possible to the printed version prepared for publication by G.P. Moss [see Arch. Biochem. Biophys. 1972, 151, 597-602; Biochem. J., 1972, 127, 753-756; Biochemistry, 1972, 11, 942-944; Biochim. Biophys. Acta 1972, 278, 211-217; Biopolymers, 1972, 11, 321-327; Eur. J. Biochem., 1972, 26, 301-304; J. Biol. Chem., 1972, 247, 323-325; Pure Appl. Chem., 1973, 33, 437-444; Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 70-72. A PDF of the printed version is available. copyright IUPAC and IUBMB; reproduced with the permission of IUPAC and IUBMB]. If you need to cite these rules please quote these references as their source. In the web version footnotes have been converted into notes following the paragraph to which they apply.
Any comments should be sent to any member of the Committee
This revision differs from the original (ref 1) essentially in the addition of comments after Recommendation 1 and in the relevant "Examples." These revisions were made to conform with the practices in polymer chemistry and were recommended to CBN by the IUPAC Commission on Macromolecular Nomenclature (IUPAC Information Bulletin, Appendices on Nomenclature, etc., No. 13, February 1971) and the Nomenclature Committee of the Division of Polymer Chemistry of the American Chemical Society (see Macromolecules, 1, 193, 1968).
Contents
These proposals are based in large part on the abbreviated nomenclature devised by Gill (ref 2) and by Sela (ref 3) and others. They utilize the symbols and conventions set forth in Section 2 of "Revised Tentative Rules for Abbreviations and Symbols of Chemical Names of Special Interest in Biological Chemistry" (ref 4) and in "Abbreviated Designation of Amino Acid Derivatives and Peptides" (ref 5), and they add only those terms or conventions needed for the specification of polymers but not encompassed by these schemes.
The symbols and conventions of the previous "Tentative Rules" (ref 4, 5) used in this nomenclature system are summarized as follows. The symbols of the amino acid residues and their derivatives or modifications are those indicated in the "Tentative Rules" (ref 4, 5) or formulated according to the principles set out in thern. Hyphens or commas between the symbols for residues or groups of residues indicate known or unknown sequence, respectively, and involve only the α-NH2 and α-COOH groups (the peptide link). Commas may be omitted when other symbols (e.g. subscripts or superscripts) separate symbols in unknown sequences. Vertical strokes indicate covalent bonds involving functional groups or the remaining H-atom of the peptide bond, depending upon their placement (ref 5). L-Amino acids and α-peptide links, read from left (NH2 terminus) to right (COOH terminus), are assumed unless indicated otherwise (ref 4, 5).
1. Linear Polymer.. All amino acid residues (constitutional units) are linked in an unbranched chain.
2. Block: A polymer that forms a distinct part of a larger polymer (e.g. a block or graft polymer may contain several blocks).
3. Graft Polymer: One or more blocks are linked to the functional groups of a linear polymer, thus creating a branch or branches. (Functional groups include ε-NH2, β- or γ-COOH, etc., and the remaining H-atom of an α-peptide link.)
4. Block Polymer: Two or more species of block are linked to form a larger linear polymer.
1. Designation of Blocks or Linear Polymers. The prefix "poly" or the subscript n indicates "polymer of". It is attached to each main chain and is repeated in each block within a larger polymer unless there is sufficient indication of size and of structure to make this repetition unnecessary. For example, poly(Glu) or (Glu)n. represent poly(glutamic acid), and (Glu)10, a decapeptide of glutamic acid. "Oligo" may replace "poly" for short chains.
Comments
a) n replaces the p as originally, but no longer, used in the polymer nomenclature scheme devised by the IUPAC Subcommission on the Nomenclature of Macromolecules (ref 6). It is used in designating polynucleotides (ref 7), and it is chosen in place of p in order to avoid confusion with the "p" used for a terminal phosphoric residue in the latter scheme. The n may be replaced by a definite number (e.g. 10 above), an average (e.g. ), or a range (e.g. 8-12), as appropriate. However, two n's should not appear in the same formula unless equal length is implied. When equal length is not the case, different letters should be used, such as m, j, k.
b) If "poly" is used rather than the subscript n, the symbol (s) following "poly" should be enclosed in parentheses with no intervening space, e.g. poly(Lys). If "poly" is followed by a single, simple word, the whole is written as one word, e.g. polylysine. If what follows "poly" is complex, it should be enclosed in parentheses (again without following space), e.g. poly(amino acid), not polyamino acid or polyaminoacid; poly(glutamic acid) or polyglutamate, but not polyglutamic acid; poly(DL-alanine,L-lysine) for the substance shown in Example 2; and poly(DL-alanine-L-lysine) for the substance shown in Example 3. The format poly(L-lysine) is preferred to poly-L-lysine, i.e. L-lysine is regarded as a complex term. Similarly, poly(hydroxyproline), not polyhydroxyproline.
2. Designation of Branches and Branch Points. Branches (side chains) connected to the main chain can be designated in one of three ways: by a vertical line joining the main chain and the branch (side chain); by an extended bond joining the appropriate residues with the main chain written first; or by a horizontal double dash (not preferred).
The branch points are indicated by the origin and terminus of the vertical line. If the origin is unknown, the line originates at the "p" in "poly," if "poly" is used, or at the first parenthesis (bracket), if the subscript n is used (see Recommendation 1). If the origin is known, the line originates: (a) vertically at the initial letter of the appropriate symbol, if functional groups other than α-NH2 or α-COOH residues are involved; (b) vertically at the position of the appropriate link, if substitution for the remaining H-atom of a peptide link is involved; or (c) horizontally to the left or right of the symbol, respectively, if α-NH2 or α-COOH groups are involved. The same rules apply to the termination of the line. Thus, the linkage between a side chain functional group and an α-NH2 or α-COOH group in the main chain is indicated by two perpendicular lines with the vertical line originating in the functional group and the horizontal line in the α-NH2 or α-COOH group. A number in parentheses lying beside the line indicates the number of such links per 100 residues of polymer, if known.
Comment
A limitation of the double dash as a connecting link lies in its inability to originate or to terminate definitively in a specific residue. Either the arrangement of the symbols most be such that connected ones are adjacent, or the information must be given independently.
3. Block size. A superscript outside the parentheses enclosing a block indicates the number of repeating sequences per 100 residues of polymer, and it is given to the first decimal place.
4. The Molar Percentage of a single type of amino acid residue within a copolymer, derived from the amino acid analysis and assuming copolymerization, is indicated by a superscript attached to the symbol of the residue. The molar percentages are given in whole numbers and should total 99 to 101%.
1. Simple homopolymer:
2. Linear copolymer, unknown sequence, composition not specified:
3. Linear copolymer, regular alternating sequence.
4. Linear sequence of unknown order [Composition: 56% Glu, 38% Lys, and 6% Tyr (Σ = 100%]:
(a) poly(Glu56Lys38Tyr6) or (Glu56Lys38Tyr6)n (all L)(b) poly(DGlu56DLys38Tyr6) (only Tyr is L)
(c) poly(DLGlu56Lys38DTyr6) (Glu is DL, Tyr is D)
5. Block polymer of poly(Glu) combined through the α-COOH terminus to the α-NH2 terminus of poly(Lys) [Composition: 56% Glu, 44% Lys (Σ = 100%)]:
6. (a) Known, repeating sequence (a polymer of Glu-Lys-Lys-Tyr):
6. (b) Known, repeating sequences within each of two constituent blocks of a linear polymer [Composition: 37.5% Glu, 25% Lys, 25% Tyr, 12.5% Ala (Σ = 100%)]:
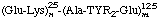
[The connection between the polymeric segments shown here is from the α-COOH of Lys to the α-NH2 of Ala. Origin or termination in any other residue or functional group can be shown by rearranging the order of residues and by the orientation of the connecting line at its origin and terminus (see Examples 7, 8, and 9).]
6. (c) Known, repeating sequence in the main chain connected by the ε-NH2 of a lysine (which of the two is not known) to an unknown point in an unknown sequence in the side chain [Composition: 30% Asp, 55% Glu, 10% Lys, 5% Tyr (Σ = 100%)]:
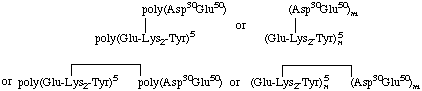
(Note: The double hyphen system is not applicable here.) If it is known which lysine residue is connected to the side chain, the main chain would be written in the form,
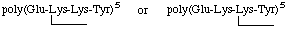
as appropriate.
7. Graft polymer with the main chain of DL-alanine and L-lysine connected through the ε-NH2 group of lysine to the α-COOH group of L-tyrosine in the side chain, which consists of a block polymer of L-tyrosine and L-alanine (no analytical data for the main chain):
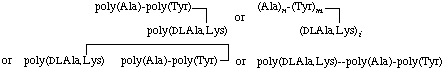
(Note: The points of attachment of Lys and Tyr cannot be specified in the last example.)
8. Graft polymer with an unknown sequence in the main chain and in the side chain [Composition; 16% Lys, 20% Ala, 35% Glu, 29% Tyr (Σ = 100%)]:
(a) Number and position of the points of attachment in the main chain unknown, but terminating in the lysine residues of the side chain:
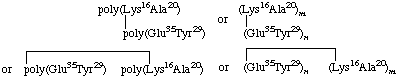
(b) Same, but attachments are 3 in number and connect the ε-NH2 groups of the lysine residues in the side chain and the γ-COOH groups of the glutamic acid residues in the main chain:
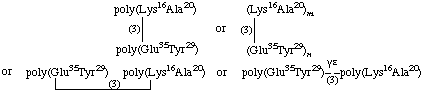
9. Graft polymer with a block polymer arid an unknown sequence in the side chain (upper) attached to an unknown sequence in the main chain (lower); the points of attachment are between the γ-COOH groups of glutamic acid in the side chain and the ε-NH2 groups of lysine in the main chain [Composition: 12% Glu, 21% Lys, 24% Tyr, 24% Leu, 20% Ala (Σ = 101%)].
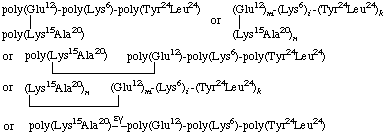
1. Biopolymers, 8, 161 (1969); Arch. Biochern. Biophys., 123, 633 (1968); Biochem. J., 106, 577 (1968); Biochemistry, 7, 483 (1968); Biochim. Biophys. Acta, 168, 1 (1968); Eur. J. Biochem., 3, 129 (1968); J. Biol. Chem., 243, 2451 (1968); Bull. Soc. Chim. Biol., 51, 205 (1969); Z. Physiol. Chem., 349, 1013 (1969); J. Mol. Biol., 5, 492 (1971).
2. Gill, T. J., III, Biopolymers, 2, 283 (1964); also J. Biol. Chem., 240, 3227 (1965); Biochim. Biophys. Acta, 124, 374 (1966).
3. Sela, M., Advan. Immunol. 5, 30 (1966).
4. J. Biol. Chem., 241, 527 (1966); Biochemistry, 5, 1445 (1966); Biochem. J., 101, 1 (1966); Virology, 29, 480 (1966); Arch. Biochem. Biophys., 115, 1 (1966); Eur. J. Biochem., 1, 259 (1967); Z. Physiol. Chem., 348, 245 (1967). See also Reference 7.
5. J. Biol. Chem., 241, 2491 (1966); Biochemistry, 5, 2485 (1966); Biochim. Biophys. Acta, 121, 1 (1966); Biochem. J., 102, 23 (1967); Arch. Biochem. Biophys., 121, 1 (1967); Eur. J. Biochem., 1, 375 (1967); Z. Physiol. Chem., 348, 256 (1967); Bull. Soc. Chim. Biol., 49,121 (1967). Revision in Preparation. [1983 edition now available]
6. J. Polym. Sci., 8, 257 (1952); revised in.1967 (see note on polymer chemistry nomenclature in the introduction before the contents list. For the 1996 edition see reference 18 of the macromolecular recommendations.).
7. Biochem. J., 120, 449 (1970); Biochemistry, 9, 4022 (1970); Eur. J. Biochem., 15, 203 (1970) [corrections 1972, 25, 1]; J. Biol. Chem., 245, 5171 (1970); Z. Physiol. Chem., 351, 1055 (1970); J. Mol. Biol., 55, 299 (1971); and elsewhere. [also available on the web and from Arch. Biochem. Biophys. 1971, 145, 425-436; Biochim. Biophys. Acta 1971, 247, 1-12; Pure Appl. Chem., 1974, 40, 277-290; Biochemical Nomenclature and Related Documents, 2nd edition, Portland Press, 1992, pages 109-114
Return to IUPAC Chemical Nomenclature Homepage